
In this article, we will understand the concept of decision trees, their components and their applications. We know that, in machine learning, classification is a two-step process, the first step is to learn and the second step is to predict.
In the learning step, we develop a model based on the sample data we have and in the prediction step, the model that is developed using sample data is used to predict the response for a given set of data.
Let’s take an example, suppose a person loves to eat pizza then that person is awesome and if that person does not love to eat pizza then the person is less than awesome.
It can be illustrated as –
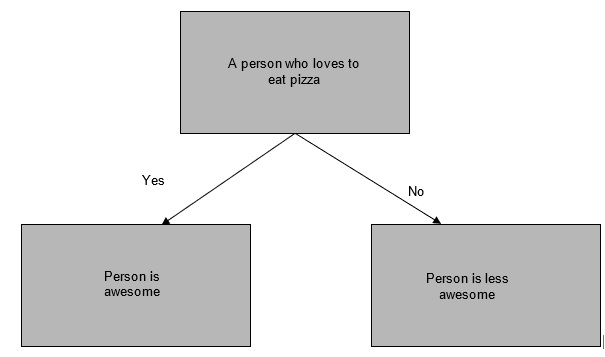
In the above example, the decision tree has asked a question and then classified the person based on the answer. The decision tree is basically a representation of all the possible solutions to a decision based on certain conditions in the form of a tree.
It’s called a decision tree because it starts with a single node, which then branches off into a number of solutions, just like a tree. It is used to solve classification problems.
The decision tree can also be categorized into yes/no questions or numeric data. The illustrated decision tree above is based on a yes/no question.
Take another example of a baby who is just born then his/her weight should be greater than 2.5 kg then he/she is considered healthy and can be taken home or else he/she needs to be kept in incubation.
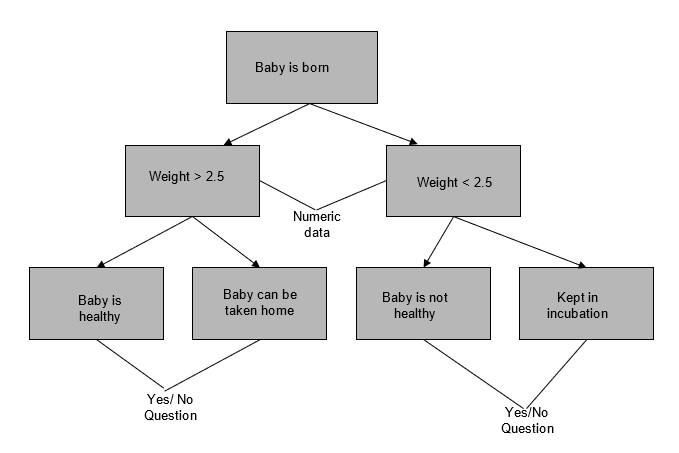
The illustrated decision tree consists of numeric data and yes/no questions. While classifying the sample using the decision tree, we start from the top and work our way till down until the sample can’t be further classified.
A decision tree can be formed by finding the predictor variable. A predictor variable is basically the data that is used to predict other data or outcomes.
But how can we decide which variable is a predictor variable? We have to find uncertainty in each data. The data which has the less uncertainty can become the predictor variable. The predictor variable will then split the data till it can’t be further classified.
What is the need to construct a decision tree?
Here, are a few reasons why we should use a decision tree –
- It is considered to be one of the most powerful machine learning algorithms that can be used to solve a variety of problems.
- The Decision tree can be easily interpreted.
- It can be used for classification and regression problems.
Components of decision tree –
There are various components of a decision tree. They are –
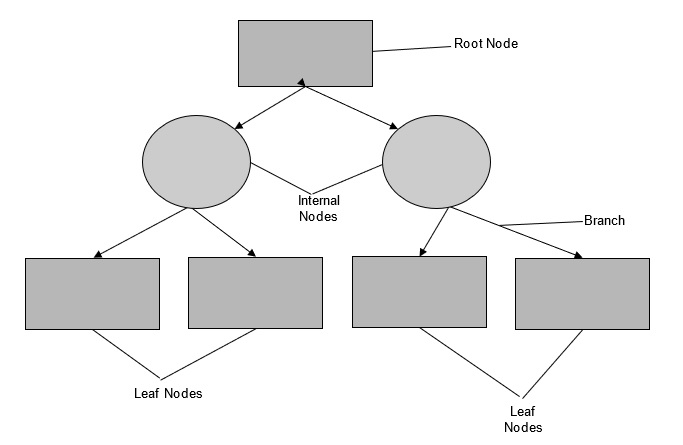
a) Root Node –
The top of the tree is the root node or the root.
b) Internal Node –
The node below the root node is called internal nodes or nodes. Internal nodes have arrows pointing to them and arrows pointing away from them.
c) Leaf Node –
These are the nodes that have no additional nodes coming off them. They are also called leaves. Leaf nodes have arrows pointing to them and but there are no arrows pointing away from them.
d) Branches-
They are used to establish a connection between various nodes. They are represented by an arrow. Each branch represents a response such as yes/no.
The components of a decision tree are illustrated below –
Applications of decision trees:-
There are various applications of decision trees. Some of them are:-
- Decision Trees are being used in the healthcare industry to improve the screening of positive cases in the early detection of people who have trouble learning, concentrating or making decisions that affect their everyday life. It is called cognitive impairment.
- Many robots that are developed today use decision tree algorithms to chat with humans.
- It is also used to predict the causes of disturbances in the forest such as wildfire, logging of tree plantations, large- and small-scale agriculture, and urbanization by using decision trees to recognize different factors of forest loss from satellite images.
- It is also used in agriculture to predict different types of crops and their stages of growth.
- Decision trees act as a great tool to perform sentiment analysis of texts and identify their emotions behind them. Basically, Sentiment analysis is a process that is used to learn about the choices and decision of customers.
- They also used to improve financial fraud detection. Decision trees are trained with several sources of raw data to find patterns of transactions and credit cards that match with cases of fraud.